Android File Sharing
The goal of this project is to develop a fast file sharing system for vehicular network. When 2 devices encounter with each other, one need to decide quickly whether the other device has the file it need or not and try to get as many data as possible. Over time, files can be shared in the whole network.
Introduction
In this work, We are trying to build a fast file sharing system between mobile devices in vehicle network.
Our problem can be simply described as that when 2 mobile devices encounter with each other, one need to detect quickly whether the other one has the file it need and furthermore, we can divide files into chunks and use some algorithm to identify the existense of the chunks. In the real case, it could be multiple devices sharing files at the same time.
First, Before we search the peers, we need do some intialization work, such as read file list and set up data structure.
After we find the peers, We will connect peers via wifi direct. The wifi direct has many limitations, like crash problems, only in android 4.0 device, and all the devices need open wifi-direct all the time to wait for connection. Since it is convenient, we will use it to simplify the work, and we will focus on developing the protocols and algorithm.
After connecting with peers, we will establish socket communication.Then we need use some protocols to check the files needed and availability and the exact chunks needed and availability.Hash tables, Bitmap and Bloom filter will be used to detect whether an element is a member of a set.All these work will be done in the query process.
The last part is data transmission. After all the work set, we can transmit the data based on the requirement. Then the file status will be updated in the file list.
According our test, we realized the idea of file sharing in a fast changing network. The transmission is stateless and after certain amount of time, the files will be finally distributed in the whole network.
Our problem can be simply described as that when 2 mobile devices encounter with each other, one need to detect quickly whether the other one has the file it need and furthermore, we can divide files into chunks and use some algorithm to identify the existense of the chunks. In the real case, it could be multiple devices sharing files at the same time.
First, Before we search the peers, we need do some intialization work, such as read file list and set up data structure.
After we find the peers, We will connect peers via wifi direct. The wifi direct has many limitations, like crash problems, only in android 4.0 device, and all the devices need open wifi-direct all the time to wait for connection. Since it is convenient, we will use it to simplify the work, and we will focus on developing the protocols and algorithm.
After connecting with peers, we will establish socket communication.Then we need use some protocols to check the files needed and availability and the exact chunks needed and availability.Hash tables, Bitmap and Bloom filter will be used to detect whether an element is a member of a set.All these work will be done in the query process.
The last part is data transmission. After all the work set, we can transmit the data based on the requirement. Then the file status will be updated in the file list.
According our test, we realized the idea of file sharing in a fast changing network. The transmission is stateless and after certain amount of time, the files will be finally distributed in the whole network.
Block Diagram Overview
The architecture of the app
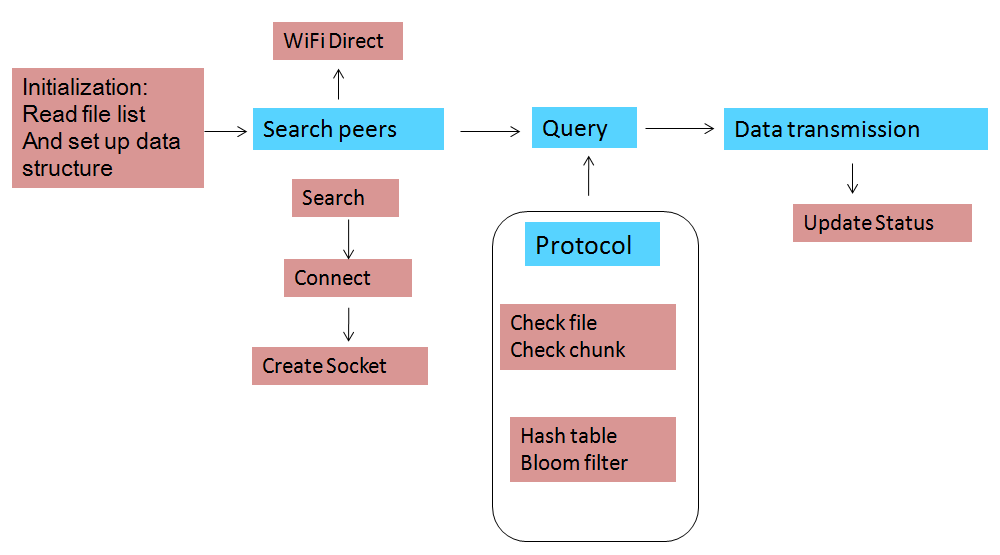
The project can be divided into several pieces according the functions which are WiFi Direct, Data Structure and Query, Client and Server and File operations. Here is the introduction of each piece in detail.
1. WiFi Direct
Wi-Fi Direct is a standard that allows Wi-Fi devices to connect to each other with no need for a wireless access point. The advantage of wifi direct are the high transmission speed, the large range of connection. But the most important motivation for us to use Wifi Direct is that it doesn't need a wifi access point or network connection. We don't need a static IP addresses and routers for the application. This is very important for a vehicular network because there is a great chance that the vehicles in the network won't know the IP of others. The basic steps for a Wifi direct application are:- Initial Setup
- Discovering Peers
- Connecting to Peers
- Transferring Data
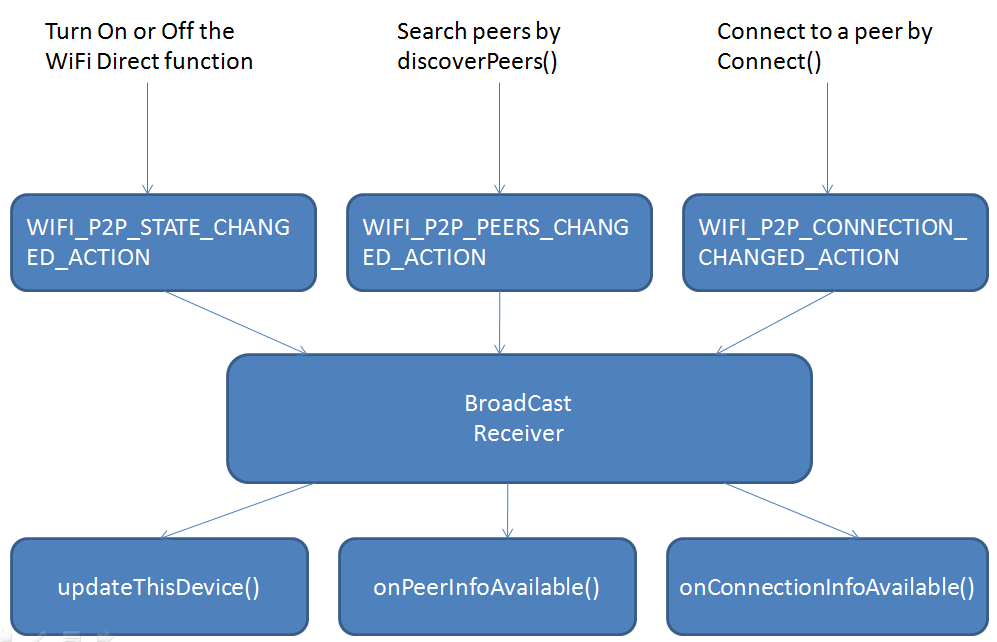
For more detailed introduction about Wifi direct, you can visit the Android Developer Guide for Wifi Direct.
Some screenshot of the wifi direct function:
| Initial Screen | Searching peers |
 |  |
| Peers list available | Select a certain peer |
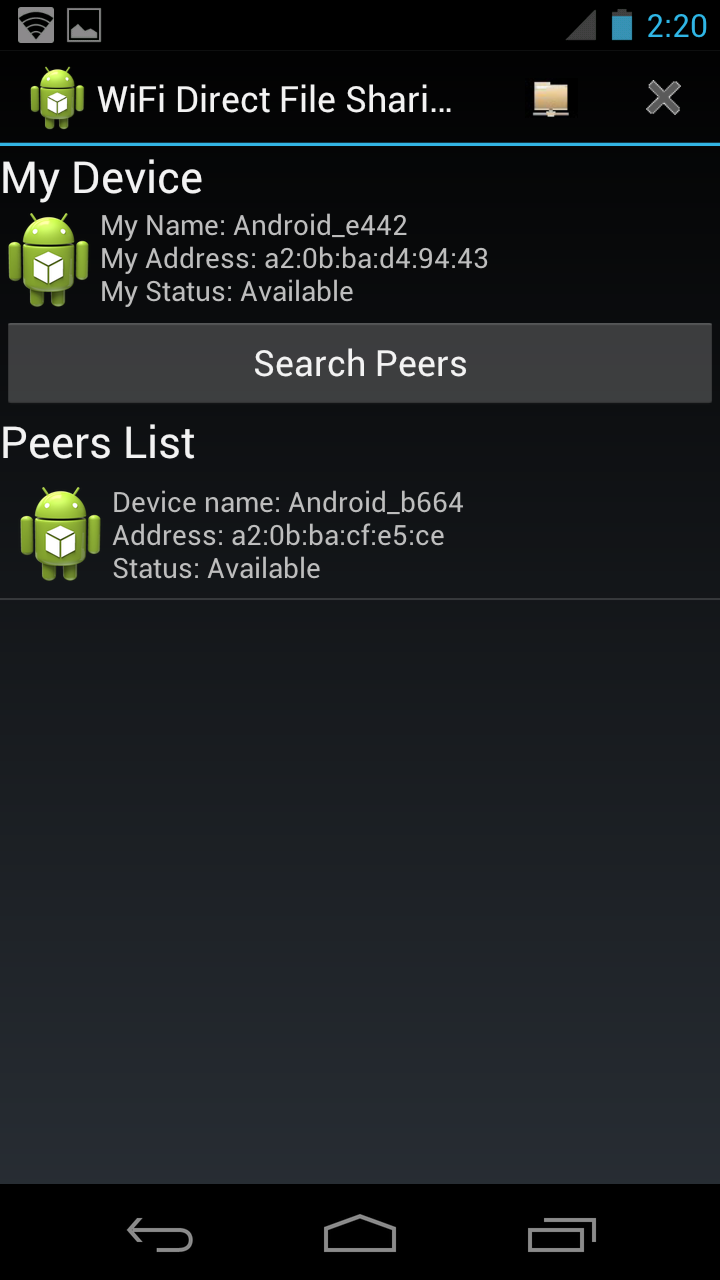 | 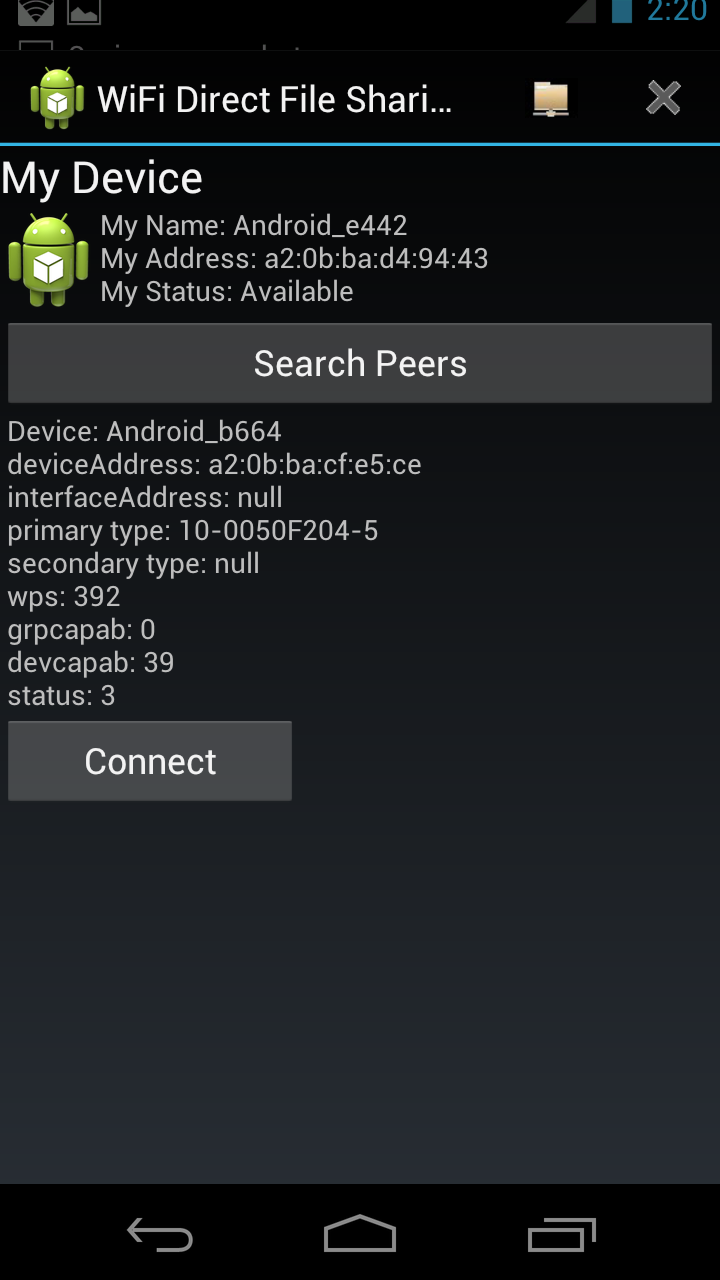 |
| Click the connect button | The other device need to confirm |
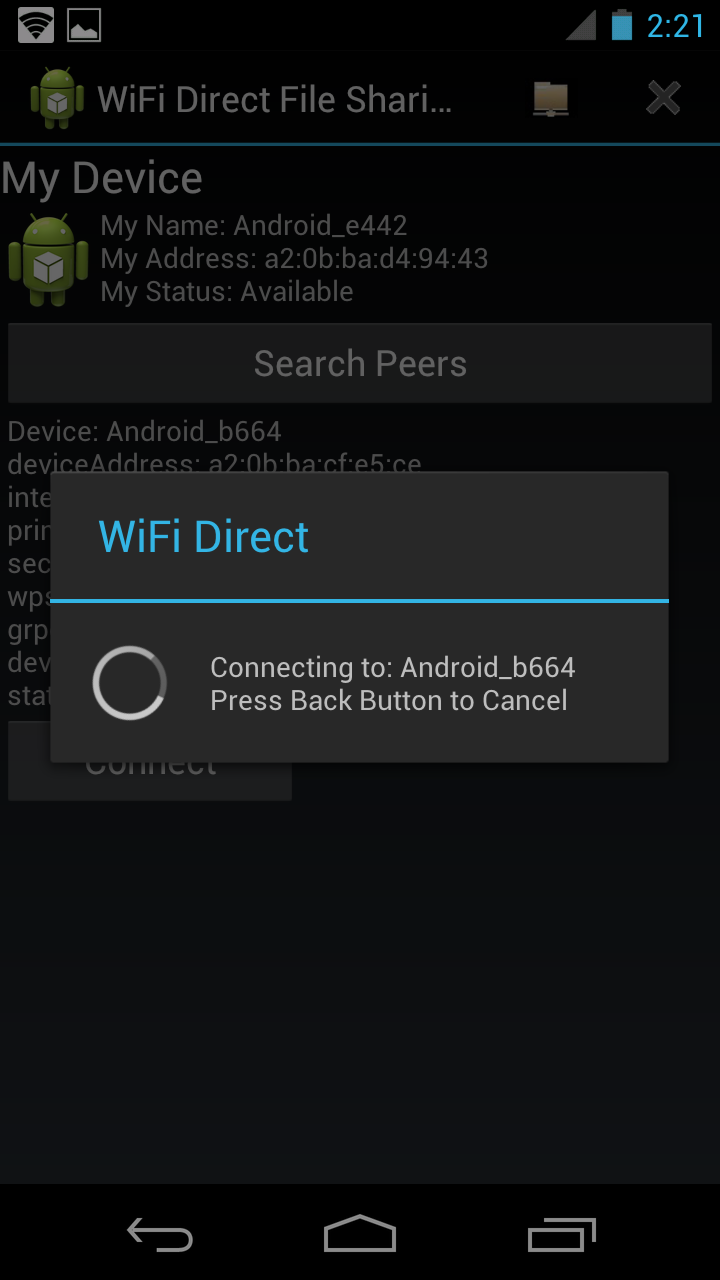 | 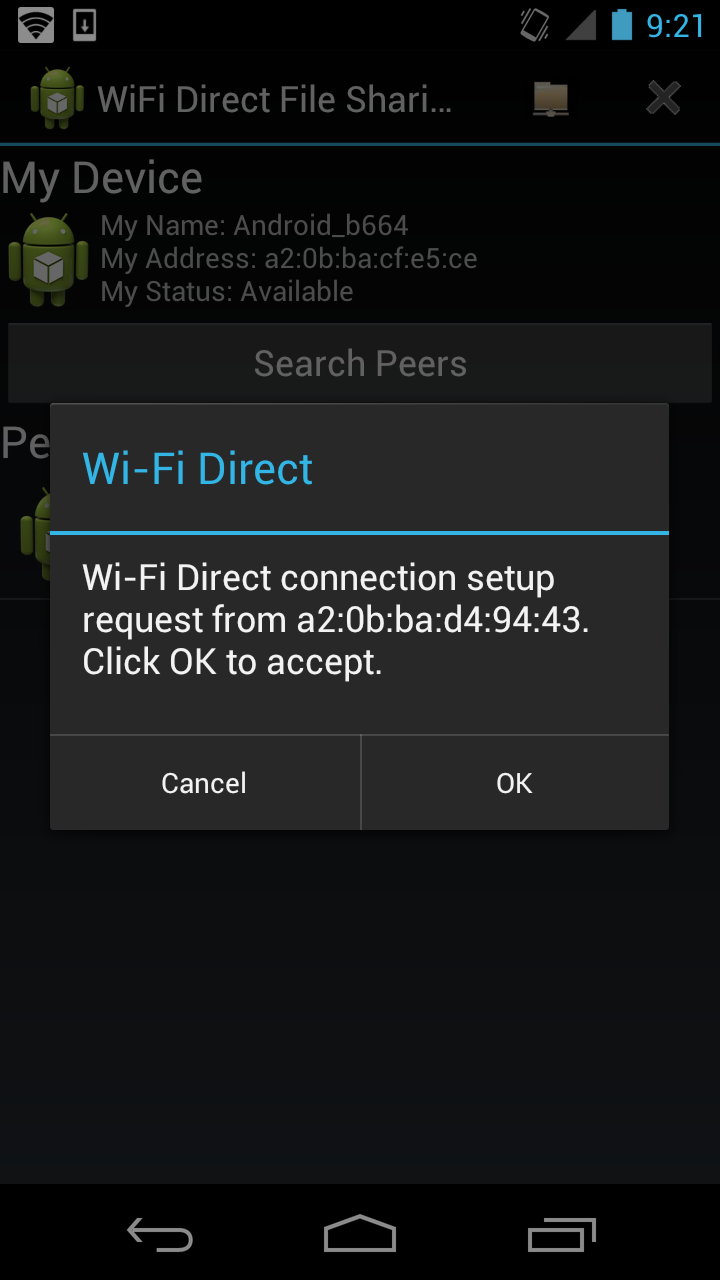 |
2. Data Structure and Query
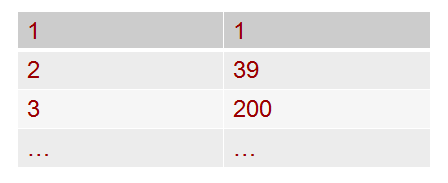
We used 2 data structure to implement the query function respectively, hash table plus bitmap and bloom filter. We have a configuration file which list out all the files need to be shared in the application, the information about the file we need are file number, file name and file size in bytes. According to that file, we can get two hash tables. One is to map the file number with the file name and the other one is to map the file number with the number of chunks in that file.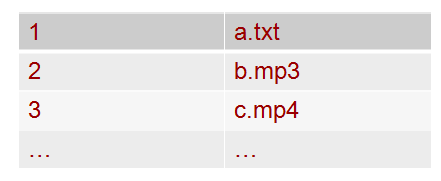
Then we need to build a table which contains all the files and chunks we already have in memory and calculate the files and chunks we need accordingly. For this info, we can use either bitmap or bloom filter.
HashTable + BitMap
For hash table plus bitmap method, the idea is to have a bitmap for each file and each bit in the map will represent a chunk of the file. if we have the chunk, we set the bit to 1. And we can map the files with their bitmap using hash table.
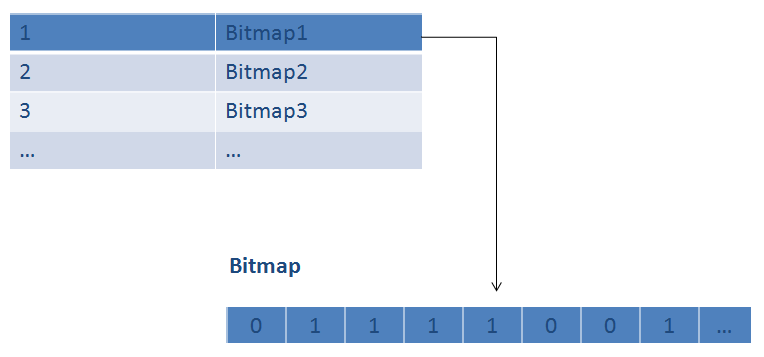
So in the query process, when we want to check if we have a particular chunk or not, we can get the bitmap of that file using the file number and then check if the corresponding bits are set to 1.
Bloom Filter
For the bloom filter method, we take advantage of the space efficiency character of this data structure and build a bloom filter with the string value of "file number - chunk number".
The way bloom filter works is like the following:
- We have several hash functions.
- For a certain “filenum-chunknum” string, calculate several hash values using those hash functions.
- Set the bit correspond to the value to 1.
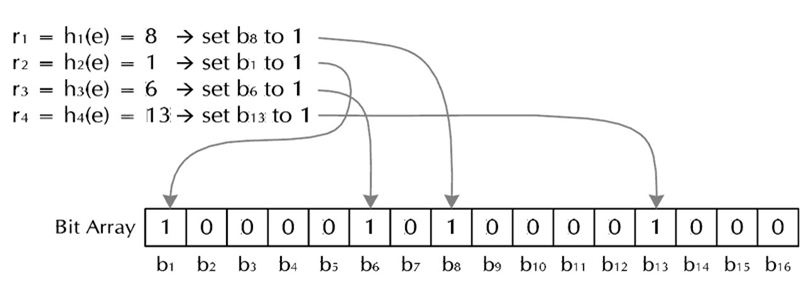
For query process, if we want to check if we have chunk No.31 of the file No.2 or not, we calculate the hash value of “2-31” again and get the values of 1,6,8,13 again. Then we check if all the bits in these positions are 1. If not, we don't have the chunk. Otherwise, we have.
The most important thing about bloom filter is to choose the number of bits for the map and choose good hash functions. Bloom filter has certain “false positive” possibility. But it can be reduced to a acceptable level with good hash functions and larger map.
Bloom filter is designed for extremely large set of data like web crawler and the advantage in space will not be visible if the scale of the application is small.
Query Process
Query is the process when one device receives a request message from another device. The request message will be introduced later. But the message will tell the device what files and chunks the other one needed. So this device need to check whether it has these files and chunks or not. If it has, then they can start the transmission.
Depending on what data structure we are using, the query is done in different ways. But the return result are the same: an ArrayList of the available chunks that the other side need. The list will contain the "file number-chunk number" string

The app then can get randomly from this list a chunk and parse the file number and chunk number and then read from the file in memory.
If the data structure we are using is bloom filter, we can read from the message about the chunks needed and test if we have the chunk using bloom filter and put the chunk number in the return list if we have. This check can be done in constant time because of the bloom filter data structure we are using.
The same idea with the hash table bitmap method. The device can read the message and get the bitmap of the other side and compared with the map of its own and build the list of available and needed chunks.
3. Client and Server
From Wifi Direct, once the connection is set up between two devices, we can get a IP address. Then we can use this IP address to create server socket as well as client socket and they can then talk over the socket connection. The basic steps for creating server and client are used. One thing need to be noticed is that Android platform requires the internet function to be done in background thread instead of the UI thread. So we used Asyctask and Handler to do this.The client and server talk to each other using certain protocol. There are 3 types of message, Request, Data and Control. The message are in the format of:

Request messages are type 1. The file number and chunk number field are empty. The data field will contain the files and chunks it need. The format is file numerb + bitmap of that file. Bitmap will save a lot of bytes for the transmission.
Data message will contains the byte stream of one chunk of data in the data field and it need to indicate the file number and chunk number. This is type 2 message.

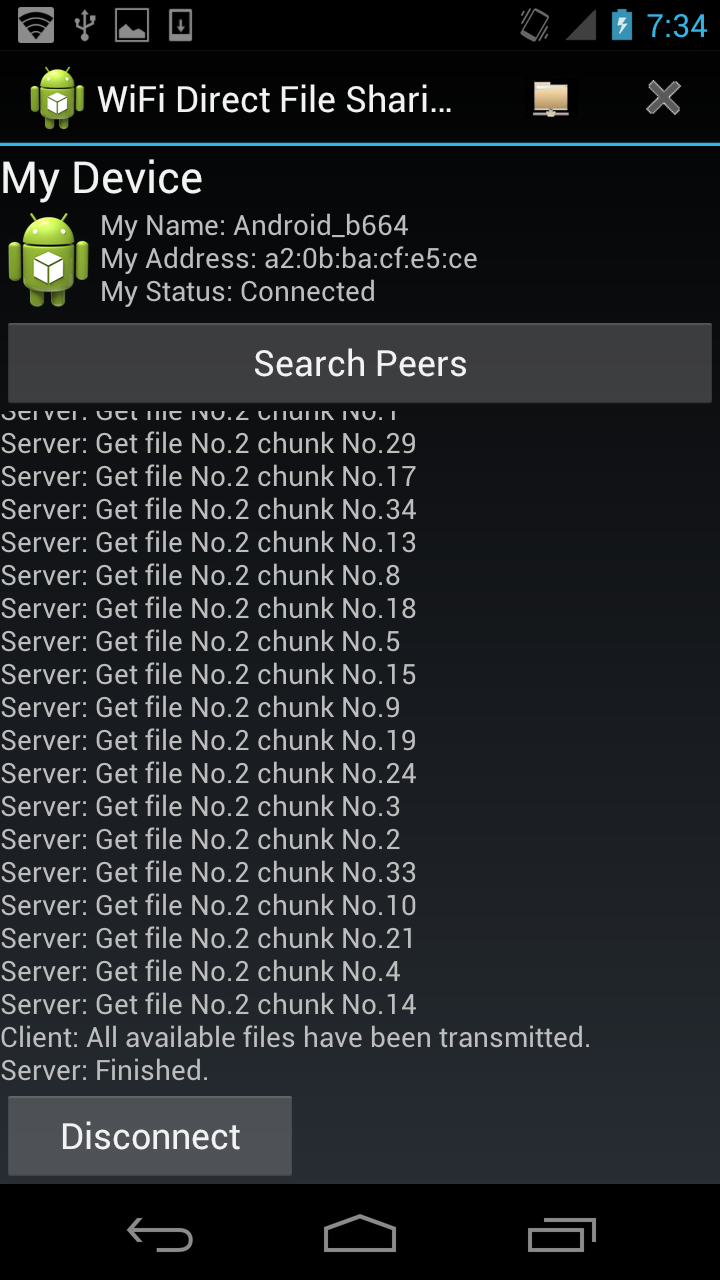
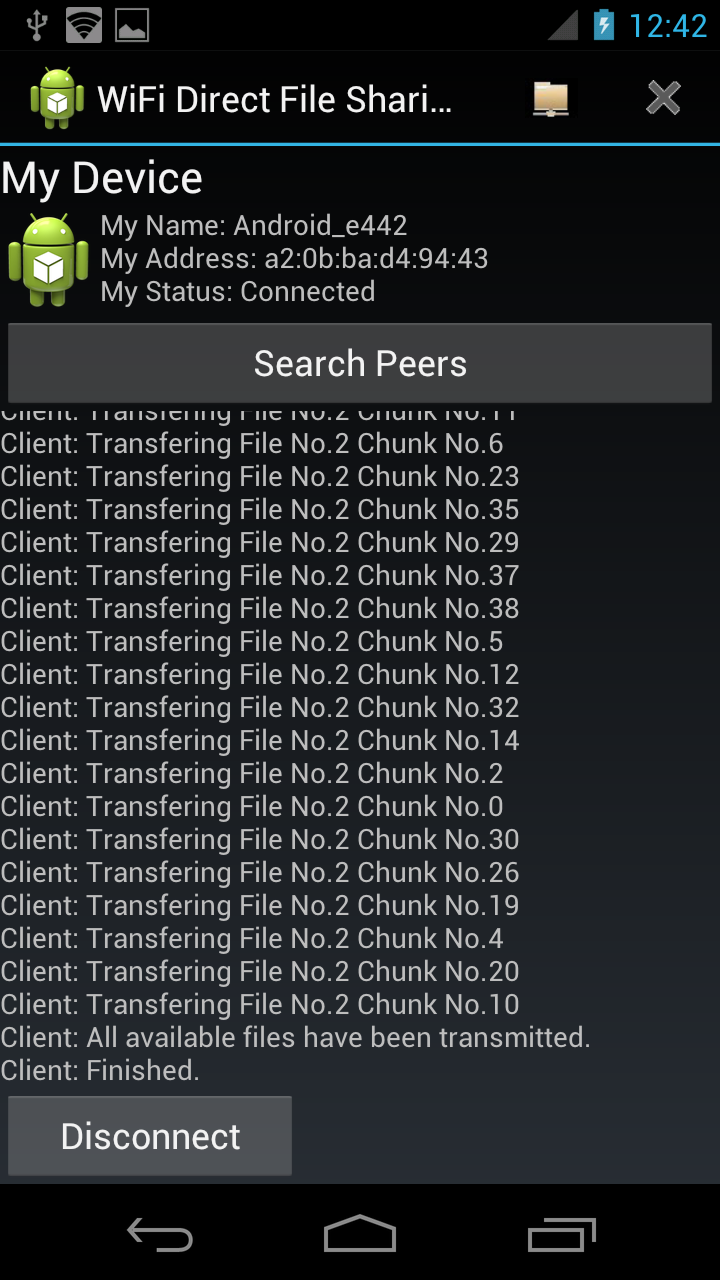
The Client Server process are similar to each other. The client will send out the request message upon connection set up and then waiting for messages from server. Server get the chunks available using query process and send data message back if there are chunks available. Client get those data message and log the chunks in temp files and update records about chunks it has. If all available chunks are transmitted, they will switch role and server will send request to client. The connection will stay unless the link is broken or all chunks available are transmitted for both sides. The flow charts of this process is as the follow:
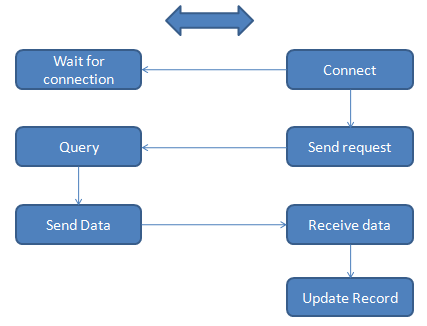
Some screen shots showing the communication between client and server:
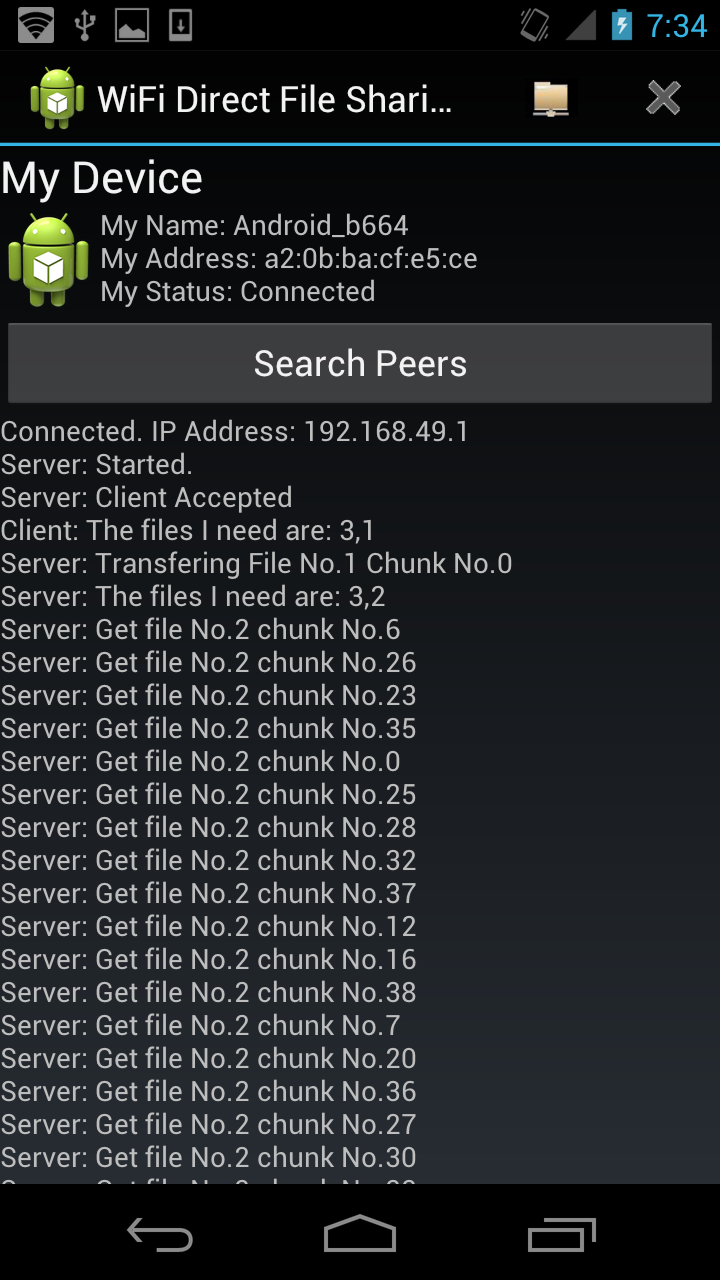
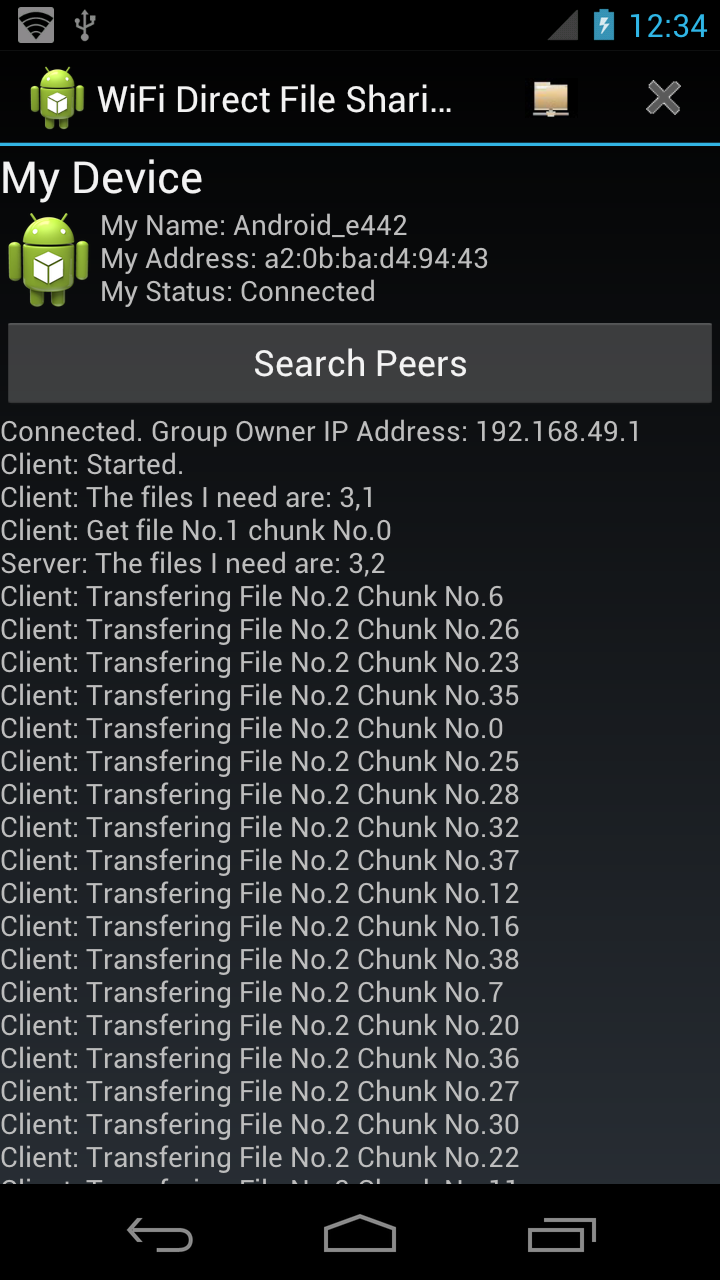
4. File Operations
File operations contain mainly two parts. One is the way we handle the file transmission and storage and the other one is the file browser.We set a 100KB chunk size and handle files by chunks. Once a device receive a chunk, it will store the chunk into a temporary file with extension tmp in the tmp folder. The file name will be "file number - chunk number.tmp". Also we need to update the record about the chunks we already have. So that we won't ask for that chunk again and we can share with others for this chunk. If we don't have the entire file, we will keep collecting the chunks. And at the mean time, we can send these chunks to other devices if necessary. The chunks are the basci unit of the application and all operation is done in chunks.
Once we have all the chunks of a file (we have a record about the number of chunks of each file from the initialization process), we can combine these chunks into a single file and delete these tmp files. The combination is pretty straight forward. We just read from these tmp files and store them into one file in turn. Only thing to notice is the actual number of bytes from each file.
The file browser enable us to check the directories easily and play audio and video easily. It use the default activities provide by the Android OS to execute the files according to the file type.
Some screenshot about the file operations:
| Device A has a.txt | Device B has b.mp3 |
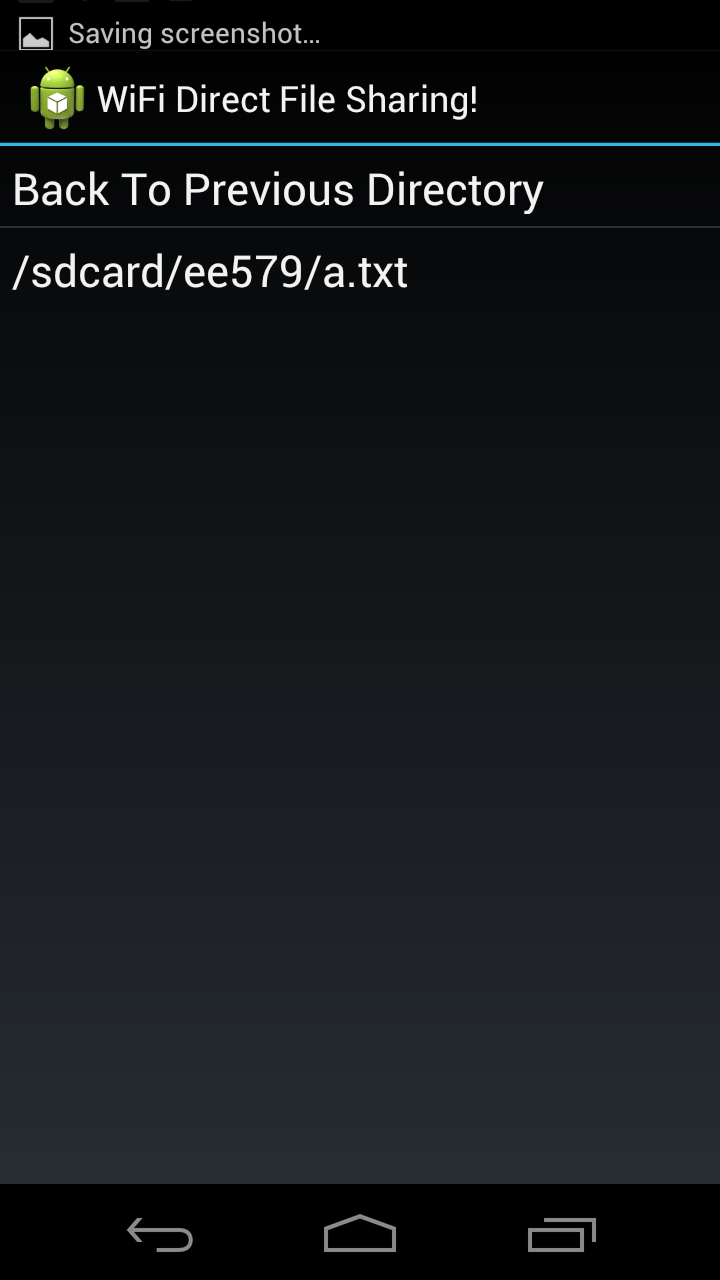 | 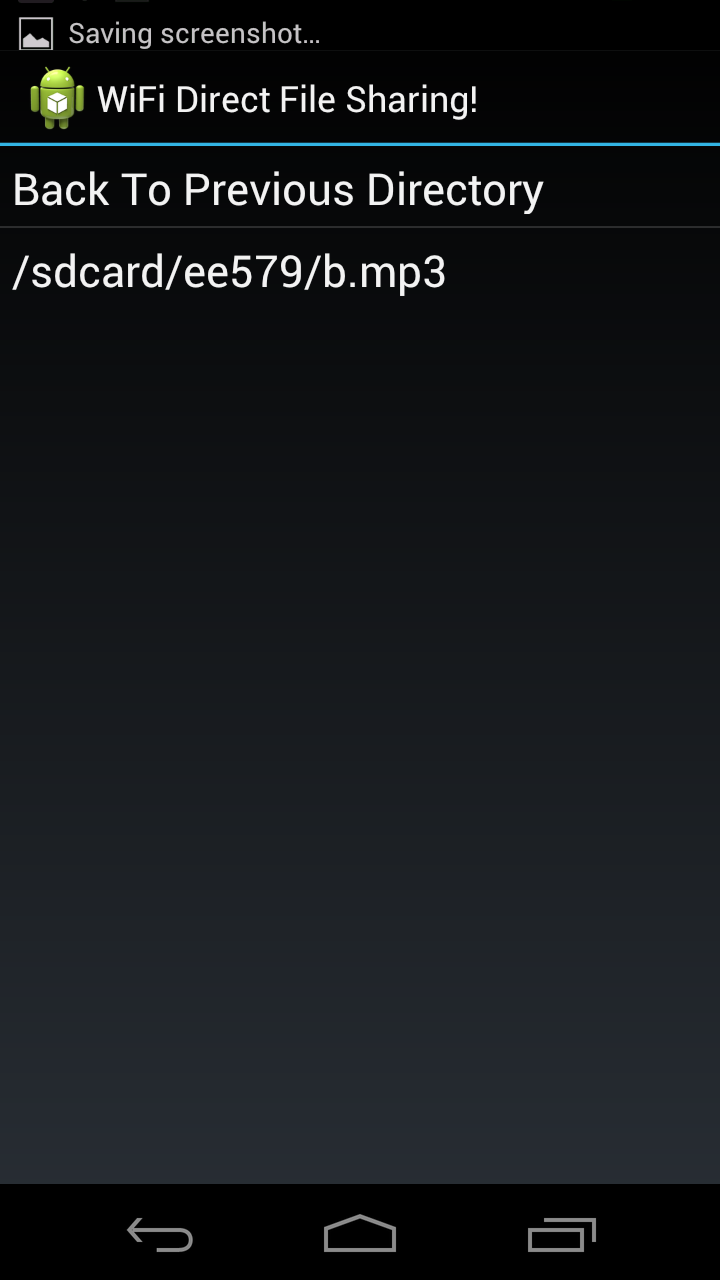 |
| Device A share a.txt with Device B | Device B share b.mp3 with Device A |
 |  |
| Device A has both files | Device B has both files |
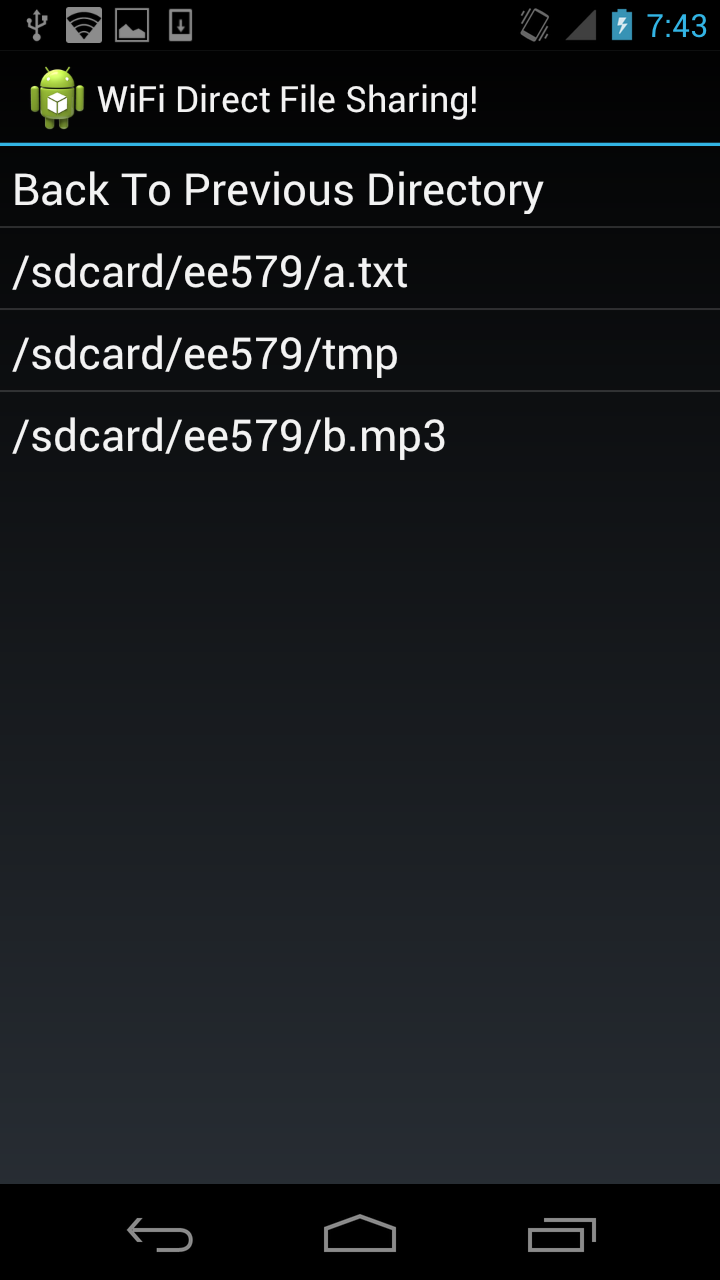 | 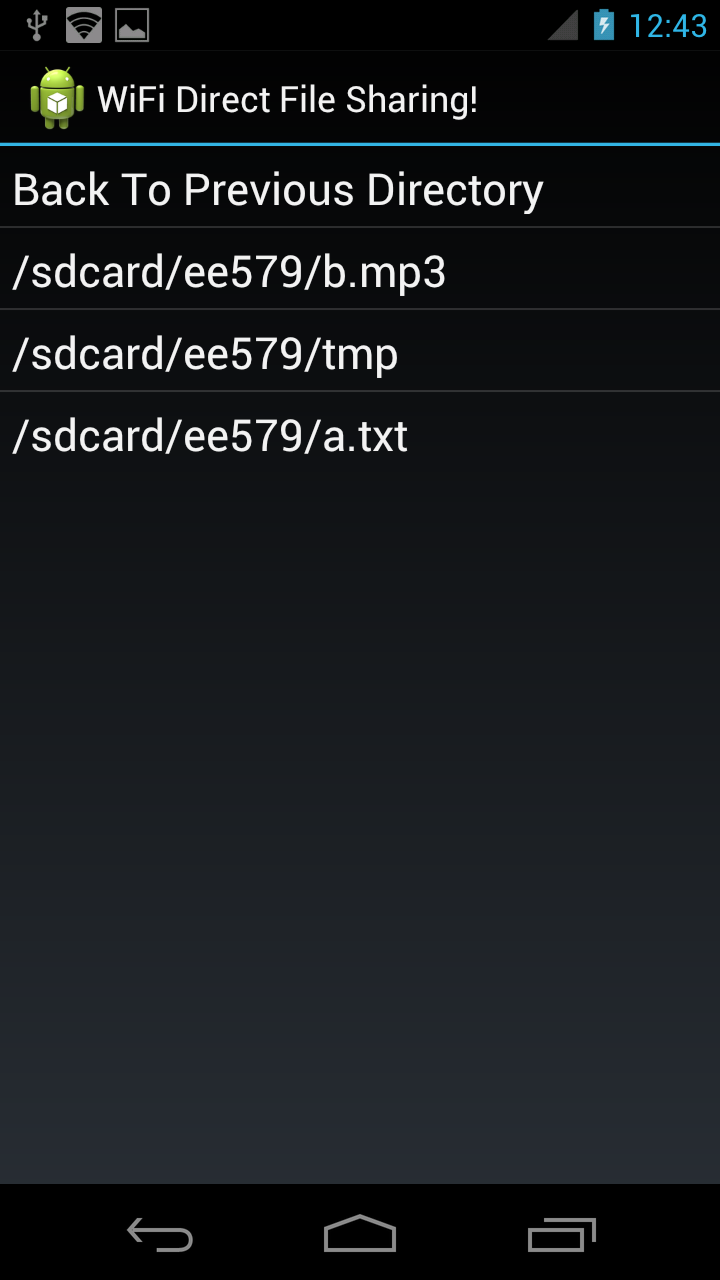 |
For more info about the design and coding of this project, please see these presentation documents.
For more detailed application in action please see the In Action part.
In action
As what we do is a vehicle based file sharing system, we have simulated the real world scenario with three test cases using 2 WiFi Direct Android device. We have 3 demo videos which will test 3 general cases for the application. Each will emulate a common situation in the real world vehicular network.
Test Case 1: Ideal case
Condition: Two mobile devices, each have one complete but different file.Operation: After a non stop connection, both devices will have 2 complete files.
Result: This case shows that if the condition is perfect which means the vehicle is stable enough and the connection time is long enough, both vehicles will have the files they don't have through a non stop connection.
Click Here to watch the demo video.
Test Case 2: Reconnection case
Condition: Two mobile devices, each have one complete but different file.Operation: Connect and transmit, stay for a while and stop the connection. Then connect again and transmit again. Both devices will have 2 complete file.
Result: This case would simulate the situation that the connection is not stable or long enough to let 2 vehicle to transmit the entire file at one time. But reconnection still works to finally get transmission done. This reconnection will simulate the situation that two vehicle may encounter and connect for a while and then pass away. And they can both encounter and connect with other vehicles. As long as other vehicles also have that file. They can finally get the entire file with several connections. The transmission is done in chunks. So it doesn't matter how many connections are needed before the entire file is transmitted.
Click Here to watch the demo video.
Test Case 3: Incomplete files case
Condition: Two mobile devices, only one devide has part of a file.Operation: Connect and transmit. After the transmission, the other one will still get the part of the file.
Result: This case simulates the situation that vehicles may only have part of the file, but still they can share that part of the file. The transmission is in the unit of chunks. So it doesn't matter the chunks are from a complete file or from just temporary chunk files. The bottom line is that the application will keep track of what chunks in which file the device has and transfer them on demand. Together with case 1 & case 2, files will finally get transmitted regardless of the quality of the connection. So over certain time, all devices in the network will have all the files.
Click Here to watch the demo video.
The three test cases are some common scenarios in the real world vehicular network where vehicles may moving fast and connection will last for a certain of time and lost. So small files may be able to be transmitted in one connection. While large files may take some time to distribute in the network. But with the ability to get any part of a file from any device in the network in any number of connections. The file sharing will finally done.
Open Source
The complete source codes and other supporting codes, documents, configuration files can be found in this Github link.
https://github.com/fanyang-usc/Android-File-Sharing
Or, you can download the zip file of this project from Here.
https://github.com/fanyang-usc/Android-File-Sharing
Or, you can download the zip file of this project from Here.
Contact
Email addresses:
Fan Yang: yang22@usc.edu
ShuSen Zhu: shusenzh@usc.edu
HanLi Guo: hamoop@gmail.com